
Configure Hadoop cluster using ansible playbooks

Hadoop is open-source software for storing data and running applications on clusters of commodity hardware. It provides massive storage for any kind of data, enormous processing power, and the ability to handle virtually limitless concurrent tasks or jobs.
RED HAT ANSIBLE
Ansible is a radically simple IT automation engine that automates cloud provisioning, configuration management, application deployment, intra-service orchestration, and many other IT needs.


Ansible is Designed for multi-tier deployments, Ansible models your IT infrastructure by describing how all of your systems inter-relate, rather than just managing one system at a time.
Task Objective :
Configure Hadoop and start cluster services using Ansible Playbook.
Configuration plan
step 1: Connect to the managed node
step 2: download JDK and Hadoop
step 3: install JDK and Hadoop
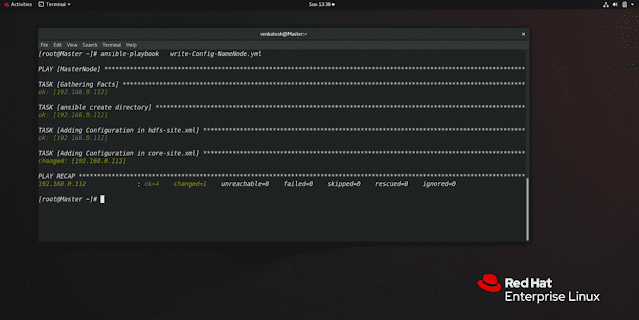
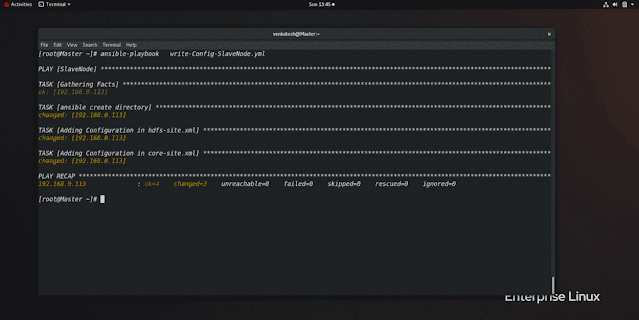
step 4: update core-site.xml and hdfs-site.xml
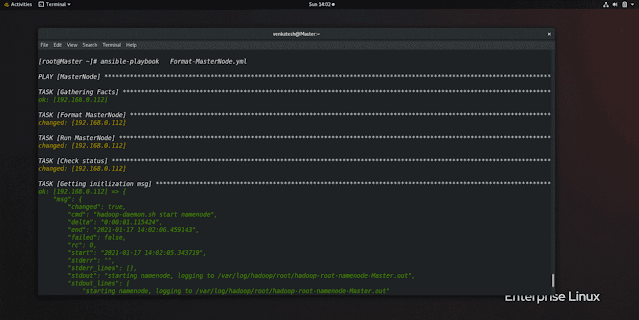
step 5: Format Namenode
step 6: start services
To get a true feeling of automation please use playbook only do not use any command in between
NOTE: all the source code is in GitHub linked provide in the last
Let’s Get Started
To install ansible run the following command:
pip3 install ansibleyou need to create an ansible directory in
etc/ansible/ // ansible directoryInventory File[Data.txt]
Ansible uses this file to check host connectivity it is a kind of IP database.
[MasterNode]192.168.0.112 ansible_connection=ssh ansible_user=root ansible_ssh_pass=root[SlaveNode]192.168.0.113 ansible_connection=ssh ansible_user=root ansible_ssh_pass=root
Configuration File[ansible.cfg]
Ansible uses this file to check its configurations.
it is located at /etc/ansible/ansibel.cfg// you need to create file[defaults]inventory = /data.txthost_key_checking = Falsedeprecation_warnings = False
step 1: Connect to the managed node
to check the connectivity of the managed node run the following command
ansible all -m ping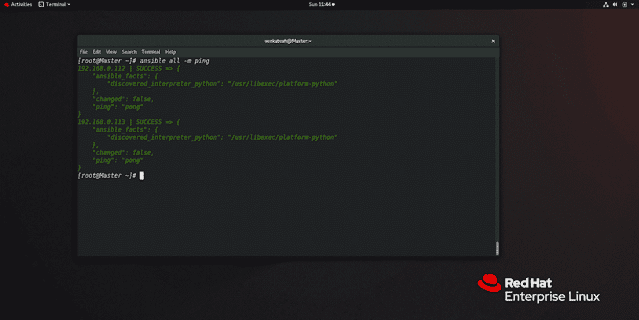
NOTE: I have already downloaded JDK and Hadoop using ansible-playbook.
Download From Here:
JDK:https://github.com/frekele/oracle-java/releases/download/8u171-b11/jdk-8u171-linux-x64.rpmHadoop:https://archive.apache.org/dist/hadoop/core/hadoop-1.2.1/hadoop-1.2.1-1.x86_64.rpm
To run Playbook use the following command
ansible-playbook FileName.yml
To transfer files between Linux system run the following command
scp -r file1 file2 'ip of destination:/path to save file'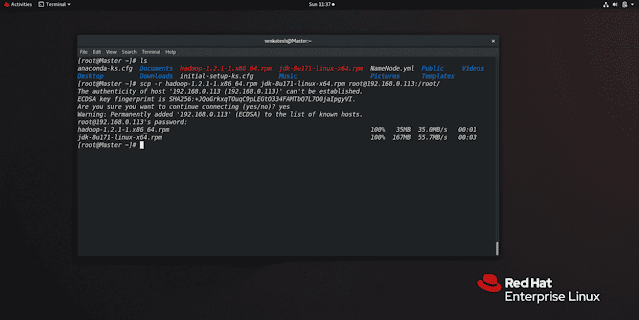
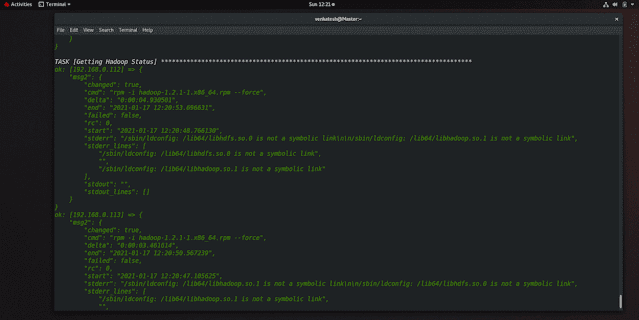
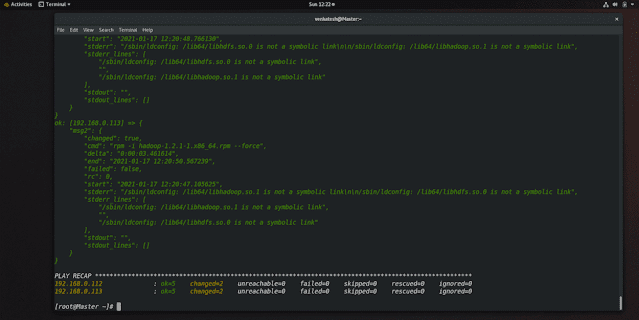
step 3: install JDK and Hadoop
to install JDK and Hadoop we have an ansible playbook you will get in my GitHub
we will use the shell module from the ansible because JDK and Hadoop is not part of yum repository
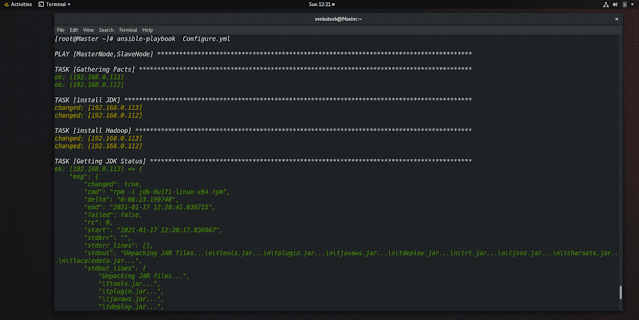
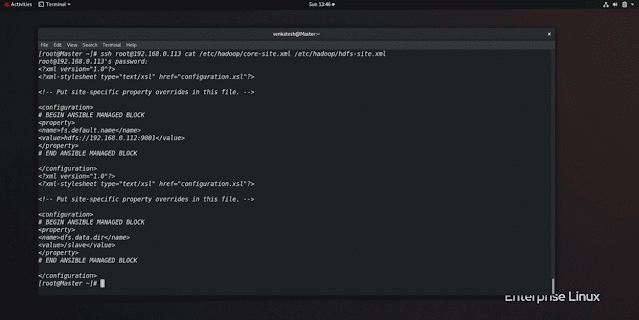
NOTE: only Hdfs-site.xml will be different in master and data node. Core-site.xml will remain the same in both.
hdfs-site.xml // will be different in both // Master Node<configuration><property><name>dfs.name.dir</name> // telling take following directory<value>/master</value> //Folder path</property></configuration>
core-site.xml // will be same in both
<configuration><property><name>fs.default.name</name><value>hdfs://192.168.0.112:9001</value> // any port you can give</property></configuration>
NameNode or MasterNode
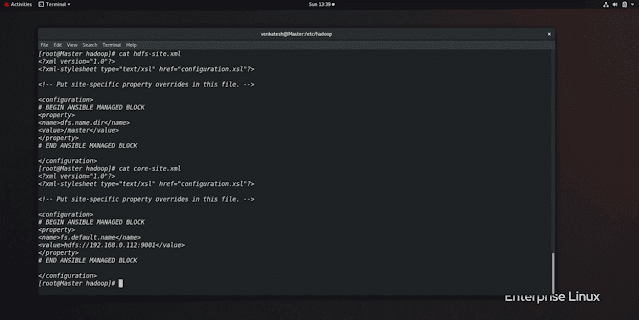
hdfs-site.xml // will be different in both // slave Node<configuration><property><name>dfs.data.dir</name> // telling take following directory<value>/slave</value> //Folder path</property></configuration>
Hadoop uses its own file system that is HDFS(Hadoop file system) so we need to format the MasterNode only no need to format slave node Because management is handled by Master Node
we have the following command to do this but we will use ansible Playbook for this as well
hadoop namenode -formatWe need to pass the command
echo Y | hadoop namenode -formatin the shell module because this command takes user input while formatting name node
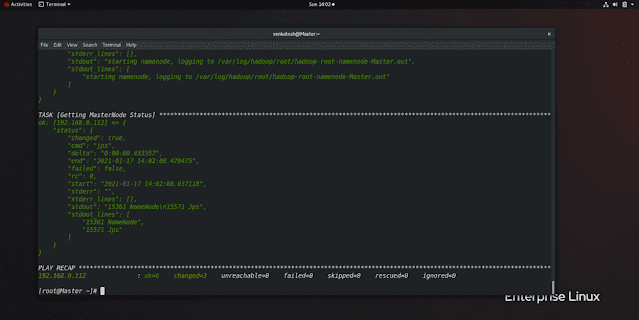
Note: MasterNode already started so we will see DataNode
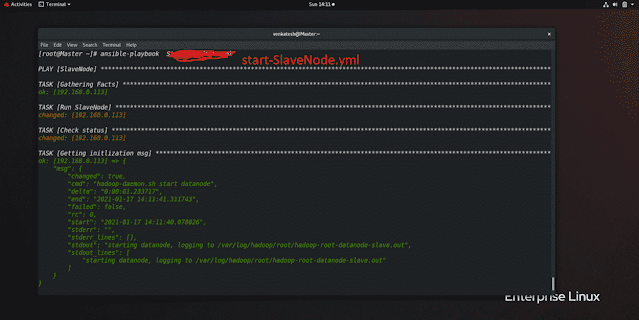
To start the Cluster services we have command but we will use ansible-playbook only
Master
hadoop-daemon.sh start namenode
// use 'stop' insted of 'start' to stop servicesSlave
hadoop-daemon.sh start datanode
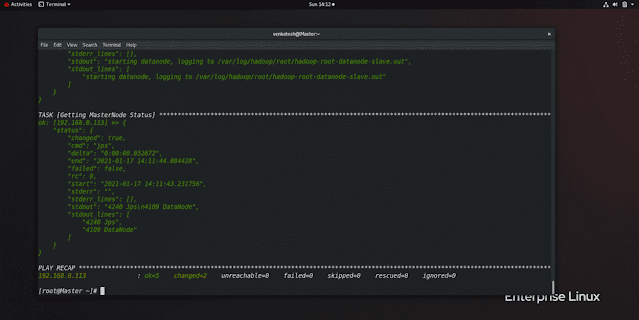
to access GUI use the following URL in the browser
http://'MasterNode IP':50070 // 50070 GUI port of hadoop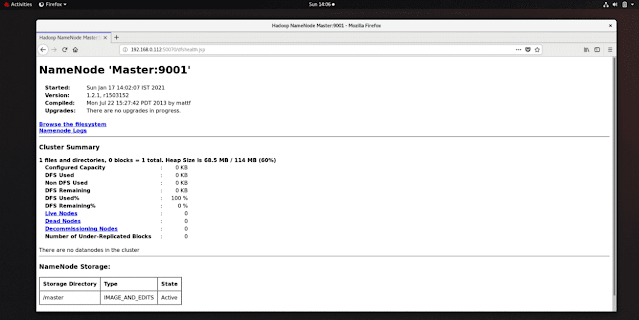

GitHub Link:
https://github.com/venkateshpensalwar/ARTH/tree/main/Ansible/Configure%20Hadoop
Conclusion:
we have learned how to configure Softwares which have clustering technology. In this way, we can set up Hadoop clusters with the help of Ansible Automation.
Hope this blog is helpful to you!!!!








No comments